

Membedah Homograph Attack: Ketika Huruf Sirilik Menipu Compiler dan User

A
I am an enthusiastic researcher and developer with a passion for using technology to innovate in business and education.
Search for a command to run...
I am an enthusiastic researcher and developer with a passion for using technology to innovate in business and education.
No comments yet. Be the first to comment.
Ringkasan: Jika OpenClaw adalah AI Operating System yang menghubungkan berbagai layanan dan agent, maka Hermes adalah AI Worker yang fokus mengerjakan pekerjaan, belajar dari pengalaman, dan semakin p

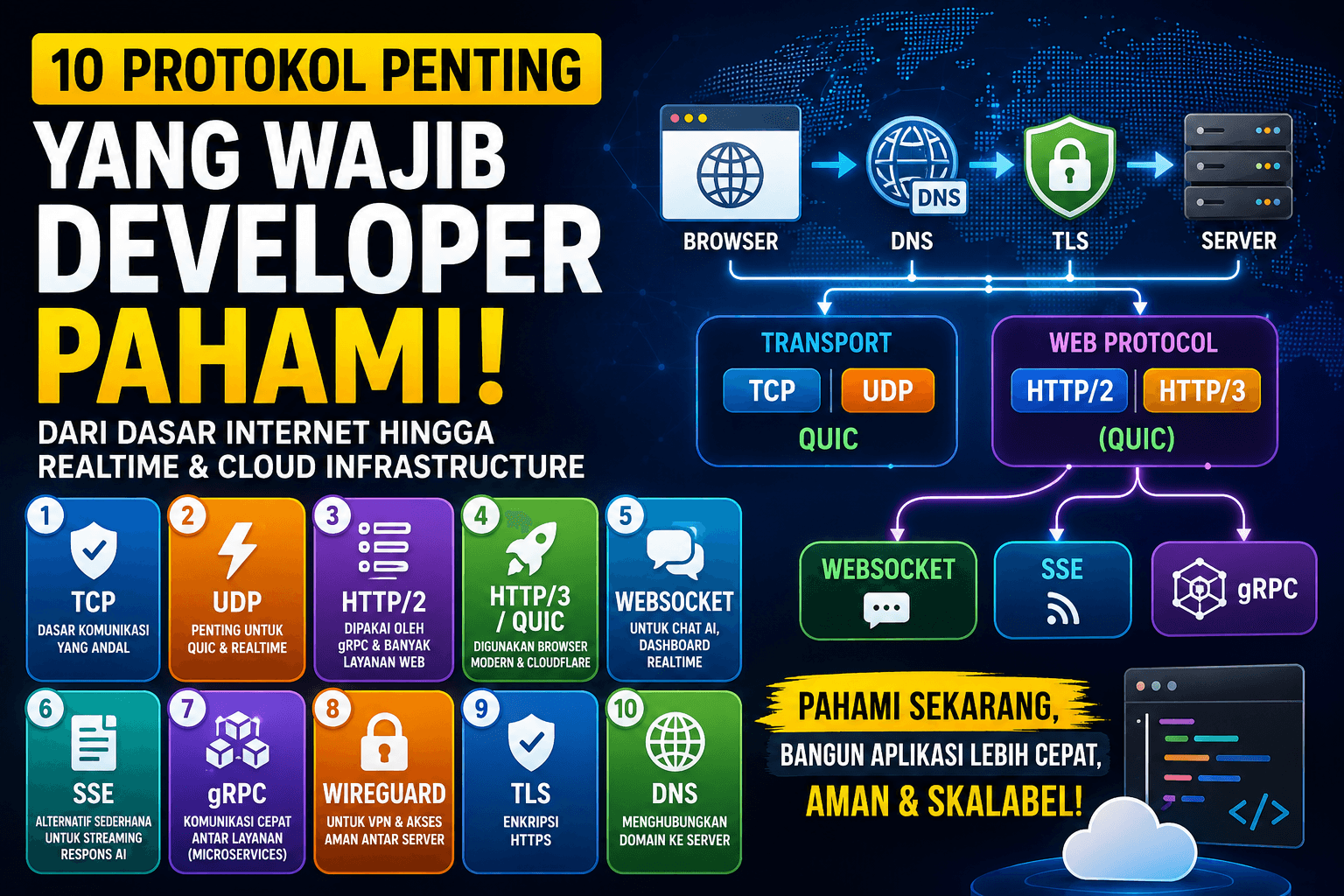
Ketika membangun aplikasi modern seperti Next.js, Cloudflare Workers, platform AI, microservices, atau real-time dashboard, ada banyak istilah jaringan yang sering muncul: TCP, UDP, HTTP/2, QUIC, WebS
Setiap tahun, ribuan mahasiswa jurusan Teknologi Informasi, Sistem Informasi, dan Teknik Informatika diwisuda. Namun, tidak sedikit di antara mereka yang kemudian menghadapi kenyataan yang cukup berat

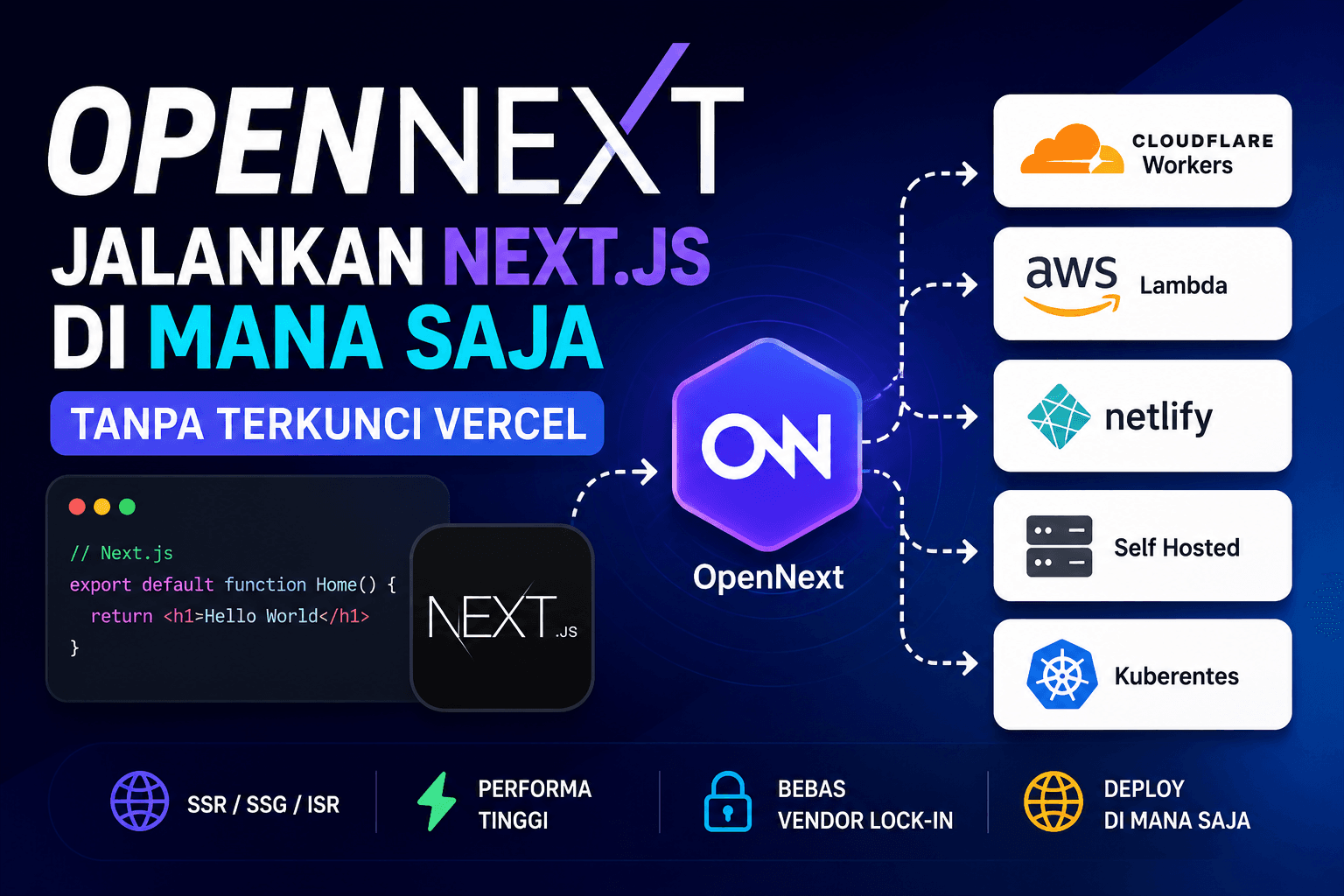
Jika Anda menggunakan Next.js, kemungkinan besar Anda pernah mendengar anggapan bahwa: "Next.js = Vercel" Padahal kenyataannya tidak harus demikian. Di sinilah OpenNext hadir. OpenNext adalah proyek
Saat pertama kali mencoba OpenCode Go, saya hampir langsung berlangganan tanpa membaca detail program yang mereka sediakan. Untungnya saya menemukan bahwa OpenCode memiliki program referral yang membe

Sebagai developer, kita sering kali mengasumsikan bahwa apa yang kita lihat di layar adalah apa yang diproses oleh mesin. Namun, dalam dunia keamanan siber, ada celah klasik yang memanfaatkan standar internasionalisasi (i18n) untuk melakukan penipuan: Homograph Attack (atau Punycode Attack).
Homograph attack adalah teknik tipuan di mana penyerang menggunakan karakter dari berbagai jenis alfabet (seperti Sirilik atau Yunani) yang secara visual identik dengan karakter Latin (ASCII).
Dalam tabel Unicode, karakter-karakter ini memiliki code point yang berbeda meskipun tampilannya sama di layar (glif yang serupa).
Karakter | Nama Unicode | Code Point |
a | Latin Small Letter A |
|
а | Cyrillic Small Letter A |
|
Bagi mata manusia, keduanya adalah "a". Bagi sistem validasi string atau browser, keduanya adalah entitas yang sangat berbeda.
Sistem DNS (Domain Name System) pada dasarnya hanya mendukung karakter ASCII terbatas. Untuk mendukung karakter internasional (IDN - Internationalized Domain Names), digunakanlah Punycode.
Punycode mengubah string Unicode menjadi format ASCII yang diawali dengan prefix xn--.
Domain Asli: apple.com
Domain Sirilik: аpple.com (menggunakan 'а' Sirilik)
Punycode: xn--pple-43d.com
Sebagai developer, fenomena ini tidak hanya relevan untuk pembuatan website, tetapi juga pada aspek berikut:
Validasi Input: Jika aplikasi kamu mengizinkan registrasi username, penyerang bisa mendaftarkan akun admin menggunakan huruf 'i' Sirilik untuk mengelabui user lain.
Security Monitoring: Log akses mungkin menampilkan URL yang terlihat normal, padahal traffic diarahkan ke server yang berbeda.
Source Code Injection: Ada kasus di mana karakter homoglyph digunakan dalam kode sumber untuk menyembunyikan logika jahat yang sulit dideteksi saat code review.
Untungnya, browser modern secara otomatis akan merender Punycode (xn--) jika sebuah domain mencampur alfabet yang berbeda (misal: Latin bercampur Sirilik) untuk memperingatkan pengguna.
Gunakan teknik normalisasi Unicode di sisi backend (seperti String.prototype.normalize('NFKC') di JavaScript) sebelum memproses atau menyimpan data user untuk mengurangi variasi karakter yang serupa secara visual.
Batasi domain mana saja yang diizinkan untuk memuat skrip atau melakukan koneksi dari aplikasi kamu guna meminimalisir risiko pengalihan ke domain homograph.
Sebagai developer, kamu bisa mendeteksi apakah sebuah string (misalnya input username atau domain) mengandung karakter non-ASCII (seperti Sirilik) menggunakan regex sederhana.
Contoh dalam JavaScript:
JavaScript
const domain = "pаypal.com"; // Ini mengandung 'а' Sirilik
const isAsciiOnly = (str) => /^[\x00-\x7F]*$/.test(str);
if (!isAsciiOnly(domain)) {
console.log("Peringatan: String mengandung karakter non-ASCII (Potensi Homograph!)");
} else {
console.log("String aman (Hanya karakter Latin standar)");
}
Keamanan bukan hanya soal enkripsi yang kuat, tapi juga pemahaman tentang bagaimana standar global seperti Unicode berinteraksi dengan infrastruktur internet yang sudah tua. Sebagai developer, kewaspadaan terhadap detail sekecil satu code point bisa mencegah celah phishing yang fatal.
Ingat: Jangan pernah percaya sepenuhnya pada apa yang terlihat di bilah alamat tanpa melakukan verifikasi pada level data mentah.