

pgvector pada PostgreSQL: Ketika Database Relasional Mulai Memahami Makna

A
I am an enthusiastic researcher and developer with a passion for using technology to innovate in business and education.
Search for a command to run...
I am an enthusiastic researcher and developer with a passion for using technology to innovate in business and education.
No comments yet. Be the first to comment.
Ringkasan: Jika OpenClaw adalah AI Operating System yang menghubungkan berbagai layanan dan agent, maka Hermes adalah AI Worker yang fokus mengerjakan pekerjaan, belajar dari pengalaman, dan semakin p

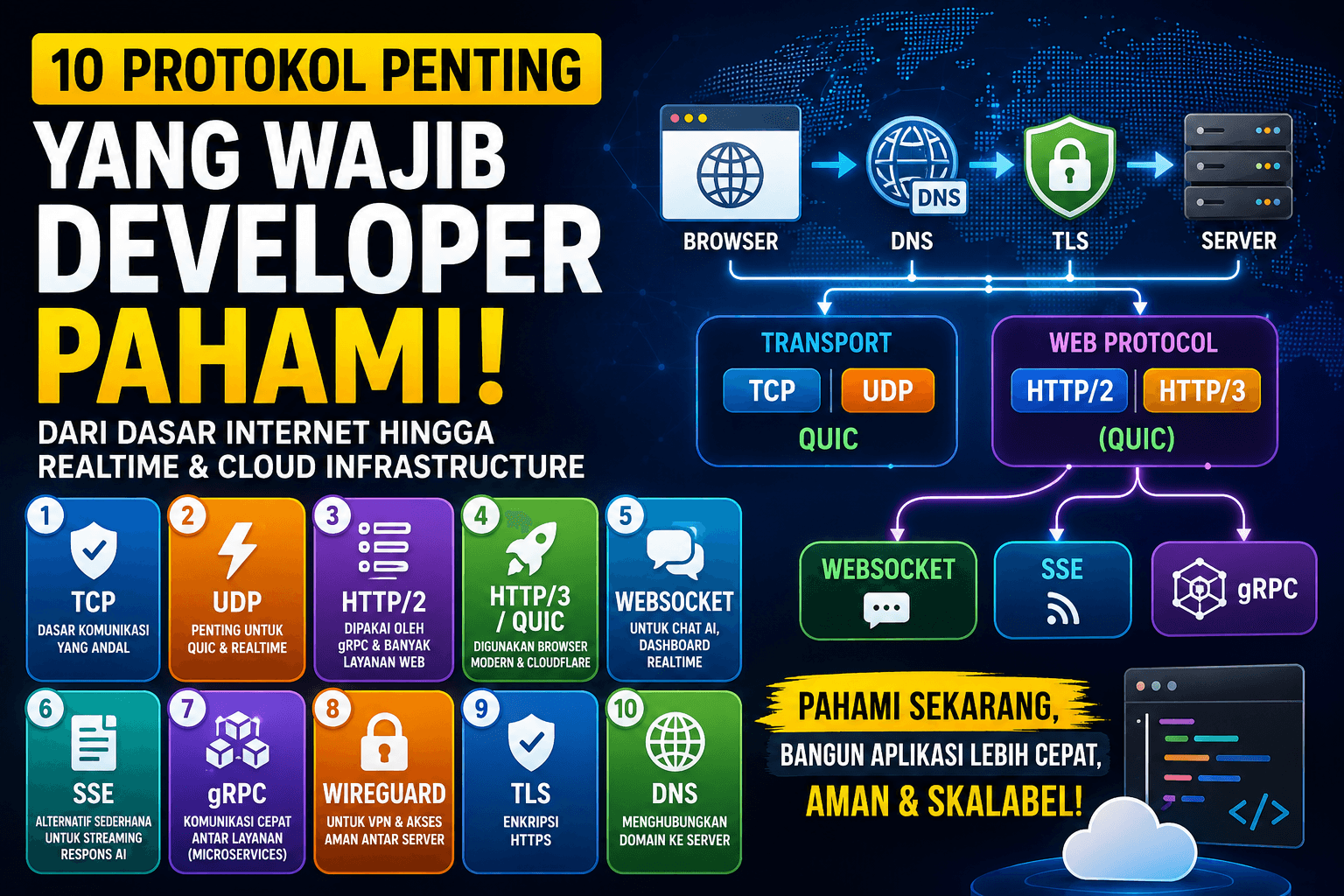
Ketika membangun aplikasi modern seperti Next.js, Cloudflare Workers, platform AI, microservices, atau real-time dashboard, ada banyak istilah jaringan yang sering muncul: TCP, UDP, HTTP/2, QUIC, WebS
Setiap tahun, ribuan mahasiswa jurusan Teknologi Informasi, Sistem Informasi, dan Teknik Informatika diwisuda. Namun, tidak sedikit di antara mereka yang kemudian menghadapi kenyataan yang cukup berat

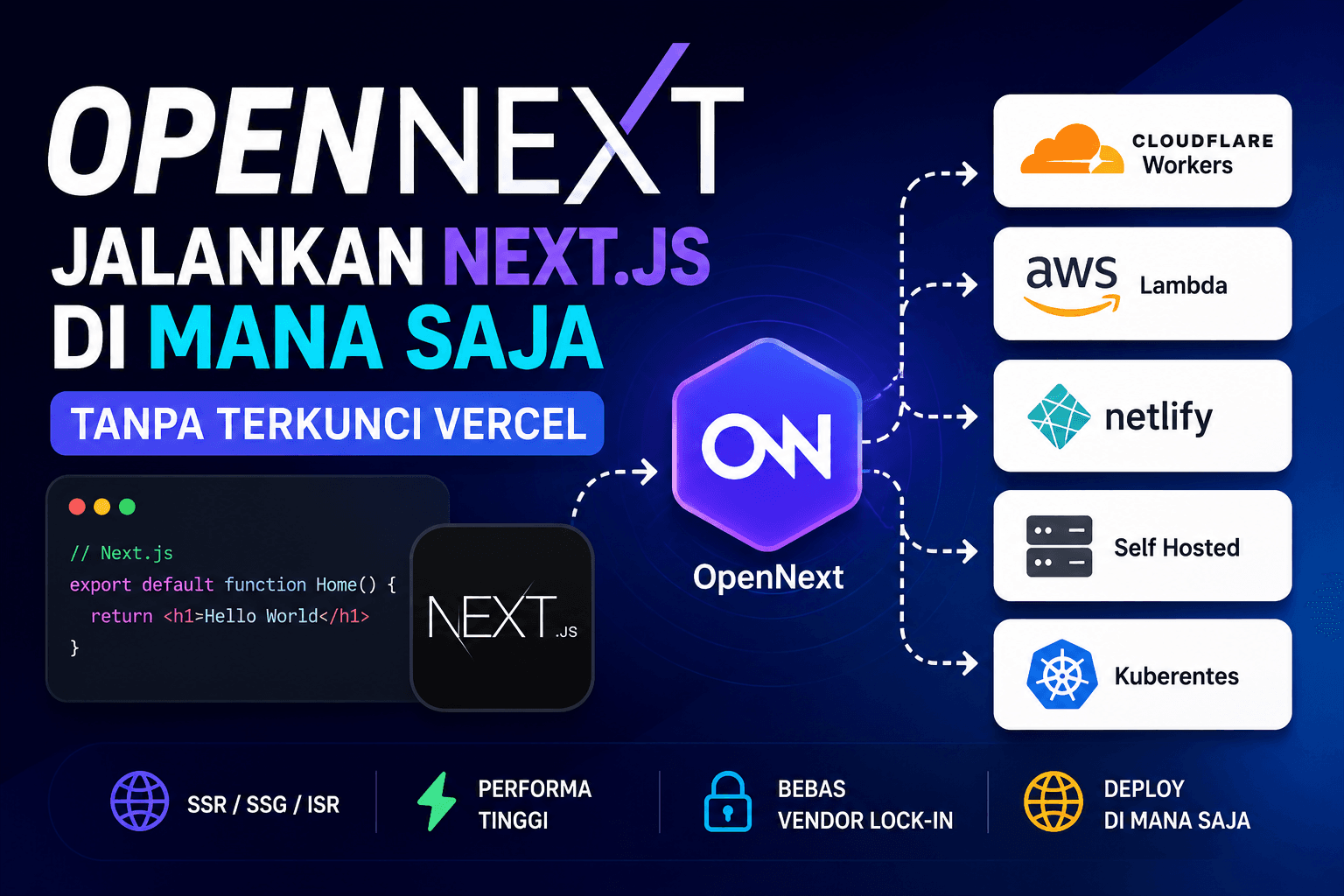
Jika Anda menggunakan Next.js, kemungkinan besar Anda pernah mendengar anggapan bahwa: "Next.js = Vercel" Padahal kenyataannya tidak harus demikian. Di sinilah OpenNext hadir. OpenNext adalah proyek
Saat pertama kali mencoba OpenCode Go, saya hampir langsung berlangganan tanpa membaca detail program yang mereka sediakan. Untungnya saya menemukan bahwa OpenCode memiliki program referral yang membe

Dunia AI modern sedang mengalami pergeseran besar. Dulu, database hanya menyimpan data terstruktur:
angka
string
relasi
transaksi
Tetapi sekarang aplikasi mulai membutuhkan kemampuan memahami makna.
Misalnya:
mencari artikel yang “mirip secara konteks”
chatbot yang bisa menjawab berdasarkan dokumen internal
semantic search
AI recommendation
retrieval untuk LLM
Di sinilah pgvector menjadi menarik.
pgvector adalah extension untuk PostgreSQL yang memungkinkan PostgreSQL menyimpan dan melakukan pencarian vector embedding secara native.
Repository resmi:
pgvector Menjadi Populer?Selama beberapa tahun terakhir, ekosistem AI dipenuhi banyak vector database:
Pinecone
Qdrant
Weaviate
Milvus
Namun banyak developer mulai mengalami masalah klasik:
App
├── PostgreSQL
├── Redis
├── Elasticsearch
├── Vector DB
└── Message Queue
Semakin banyak service:
deployment makin rumit
observability makin sulit
biaya meningkat
sinkronisasi data menjadi masalah baru
Akhirnya muncul pendekatan yang lebih pragmatis:
Gunakan PostgreSQL untuk semuanya dulu.
Dan pgvector lahir di momen yang tepat.
Embedding adalah representasi numerik dari suatu informasi.
Misalnya kalimat:
"PostgreSQL is powerful"
diubah oleh model AI menjadi:
[0.182, -0.441, 0.991, ...]
Vector tersebut menyimpan hubungan semantik.
Artinya:
“database PostgreSQL”
“Postgres DB”
“PostgreSQL server”
bisa dianggap mirip walaupun teksnya berbeda.
Inilah dasar semantic search modern.
Dengan pgvector, kita bisa membuat tabel seperti ini:
CREATE EXTENSION vector;
CREATE TABLE documents (
id bigserial PRIMARY KEY,
content text,
embedding vector(1536)
);
Kemudian melakukan similarity search:
SELECT *
FROM documents
ORDER BY embedding <=> '[...]'
LIMIT 5;
Operator:
| Operator | Fungsi |
|---|---|
<-> |
Euclidean distance |
<=> |
Cosine distance |
<#> |
Inner product |
Banyak proyek AI sebenarnya tidak membutuhkan:
cluster vector database
distributed ANN engine
kompleksitas hyperscale
Sebagian besar hanya membutuhkan:
semantic search
retrieval
chatbot context
document similarity
Dan semua itu bisa dilakukan langsung di PostgreSQL.
Inilah kekuatan terbesar pgvector.
Developer bisa menggabungkan:
relational query
filtering
indexing
vector similarity
dalam satu query.
Contoh:
SELECT *
FROM articles
WHERE
published = true
AND category = 'backend'
ORDER BY embedding <=> '[...]'
LIMIT 10;
Ini jauh lebih natural dibanding memecah query antara relational DB dan vector DB.
pgvector Sangat Cocok untuk RAGRAG (Retrieval-Augmented Generation) menjadi pola arsitektur paling populer di era LLM.
Alurnya:
User Question
↓
Embedding
↓
Vector Search
↓
Relevant Chunks
↓
Prompt LLM
↓
AI Response
Dengan pgvector, seluruh retrieval layer bisa tinggal di PostgreSQL.
Ini membuat arsitektur menjadi lebih sederhana:
App
└── PostgreSQL + pgvector
Karena masih PostgreSQL, developer tetap mendapat:
ACID transaction
replication
backup
WAL
role & permission
migration ecosystem
tooling matang
Ini penting untuk production system.
Banyak vector database belum memiliki ekosistem sekuat PostgreSQL.
pgvector Bukan Solusi untuk Semua HalIni bagian yang penting.
Banyak hype membuat developer berpikir:
pgvector = pengganti semua vector database
Padahal tidak.
pgvectorPostgreSQL adalah relational database.
Vector search hanyalah extension.
Artinya:
memory management bukan fokus vector workload
distributed ANN bukan desain utama
scaling horizontal terbatas
Satu embedding bisa memiliki:
768 dimensi
1536 dimensi
3072 dimensi
Jika ada jutaan row:
1 juta × 1536 float
ukuran storage dan RAM menjadi sangat besar.
pgvector mendukung beberapa pendekatan ANN (Approximate Nearest Neighbor).
Contoh:
CREATE INDEX ON documents
USING ivfflat (embedding vector_cosine_ops)
WITH (lists = 100);
Kelebihan:
build cepat
memory lebih hemat
Kekurangan:
Contoh:
CREATE INDEX ON documents
USING hnsw (embedding vector_cosine_ops);
Kelebihan:
hasil lebih akurat
query cepat
Kekurangan:
build berat
memory usage besar
pgvector Menjadi Pilihan Terbaik?chatbot internal
semantic FAQ
AI assistant
company knowledge base
Jika aplikasi sudah memakai PostgreSQL:
menambahkan pgvector jauh lebih murah dibanding membangun stack baru.
Developer bisa fokus ke:
produk
UX
prompt engineering
retrieval quality
bukan mengelola 5 service tambahan.
pgvector?Misalnya:
ratusan juta embedding
low latency global search
multi-region vector cluster
Dedicated vector database lebih cocok.
Jika seluruh sistem memang dibangun untuk vector retrieval skala besar:
gunakan tool yang memang dibuat khusus untuk itu.
pgvector sekarang sudah menjadi citizen utama di ekosistem AI modern.
Framework yang mendukung:
ORM dan ecosystem:
Prisma
Drizzle
SQLAlchemy
Django
Laravel
Cloud provider:
Supabase
Neon
Railway
RDS PostgreSQL
Banyak developer terlalu cepat mengadopsi arsitektur kompleks karena mengikuti hype AI.
Padahal mayoritas aplikasi AI modern sebenarnya hanya membutuhkan:
retrieval sederhana
semantic similarity
contextual memory
hybrid filtering
Dan untuk itu:
PostgreSQL + pgvector
sering kali sudah lebih dari cukup.
pgvectorKemungkinan besar pgvector akan tetap tumbuh karena:
PostgreSQL sangat matang
komunitas besar
AI adoption meningkat
developer ingin stack lebih sederhana
Ada tren kuat menuju:
Consolidated AI Infrastructure
di mana relational database mulai mengambil sebagian kemampuan AI retrieval.
pgvector bukan sekadar extension PostgreSQL.
Ia adalah tanda bahwa dunia database mulai berubah:
dari hanya menyimpan data…
menjadi mulai memahami hubungan makna di dalam data tersebut.
Bagi developer modern, ini membuka peluang besar:
membangun semantic search
membuat AI assistant internal
membangun RAG system
membuat recommendation engine
tanpa harus langsung masuk ke kompleksitas distributed AI infrastructure.
Dan mungkin itulah alasan utama mengapa banyak engineer mulai kembali berkata:
PostgreSQL first.